一、论文相关信息
1.论文题目
YOLOv3: An Incremental Improvement
2.论文时间
2018年
3.论文文献
4.论文源码
pytroch
二、论文背景及简介
YOLO v3没有太多创新,只是将一些别的地方的比较好的点融合到了YOLO v2里面,使得YOLO v2获得了比较好的提升。YOLO v3主要在三个方面对YOLO v2进行了改进。
- 利用多尺度特征进行对象检测
- 修改了基本网络结构
- 对象分类用Logistic取代了softmax。
同时,作者把该篇论文当作技术报告来写,emmmm,画风很….搞笑。
三、YOLO v3的一系列改进
1、Predictions Across Scales(多尺寸特征)
我们知道YOLO v2以及之前的版本都是对下采样32倍后的特征图进行操作。同时,为了实现细粒度检测,作者将前两层预测出来的特征图连接到了输出上。作者正是在这方面拓展,分别对下采样16倍以及下采样8倍的特征图动手。
我们先来梳理一下,假设输入为416 * 416,则相应的下采样32倍、16倍、8倍的特征图分别是(13,13),(26,26),(52,52)。
当按YOLOv2的网络结构,获得(13,13)的特征图后,对该特征图进行上采样得到(26,26)的特征图,同时将前面生成的(26,26)的特征图加到该特征图上,这样便实现了YOLO v2的passthrough,加强了细粒度检测。同理,再次上采样得到(52,52)的特征图,再把网络前面的(52,52)的特征图加上。那么,我们最后,就获得了三个大小的特征图((13,13),(26,26),(52,52)),
然后,我们分别再三个特征图上进行正常的处理(检测框的预测)
但要注意的是,YOLO v2中对特征图进行预测时,是由piror anchor的,那么我们不同大小,不同细粒度的三个特征图该如何选择anchor呢?
作者通过K均值聚类,这次设K=9,分别在三个尺寸(大中小)上选取不同的尺寸。最终作者得到的尺寸为(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。正好用在三个不同的特征图上。
当然,由于(13,13)的特征图下采样32倍,感受野大,因此能够预测大物体的可能性大,因此使用三个大的anchor来对该特征图处理。(26,26),(52,52)的依次选择中、小的anchor。
该方法极大的解决了YOLO v2对小物体预测难的问题。看一下实验结果数据。
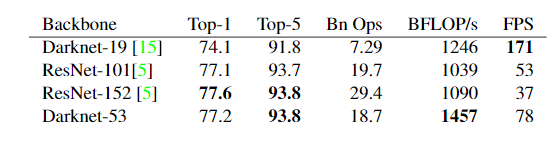
2、Feature Extractor
作者借鉴了流行的resNet的思想,给原来的darkNet添加了残差连接,并将网络扩大到了53层,极大的提高了精确度。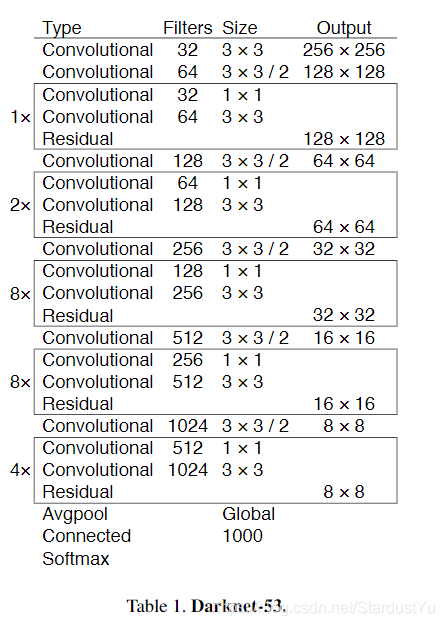
3、Class Prediction
还有一个问题就是,有些数据集中图片的标签有多个,比如女人和人。而softmax基本默认为单标签输出,因此使用Logistic 来代替softmax来实现多标签分类。
四、实验结果
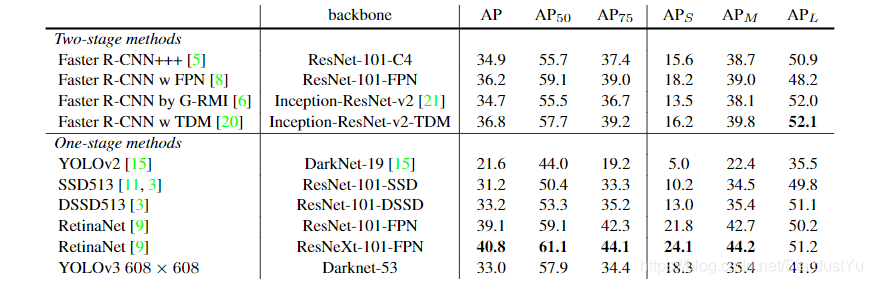
在精度上比SSD高,且时间比SSD快三倍
五、优缺点
根据实验结果,我们可以可以看到YOLO v3相比于YOLO v2极大的提高了精度,但相比于RetinaNet。精度还是不行,不过速度很快。
相比于YOLO v2,可以看到YOLO v3极大的提高了小物体预测的精度。


%E4%B9%8B%20R-CNN/cover.png?raw=true)
%E4%B9%8BFaster%20R-CNN/cover.jpg?raw=true)
%E4%B9%8BFast%20R-CNN/cover.jpg?raw=true)
%E4%B9%8BYOLOv1/cover.png?raw=true)
%E4%B9%8BMask-RCNN/cover.png?raw=true)
%E4%B9%8BYOLO%20v2/cover.png?raw=true)